p5LiveMedia is a new p5js library for sharing live audio, video, canvas (as video), and data between users.
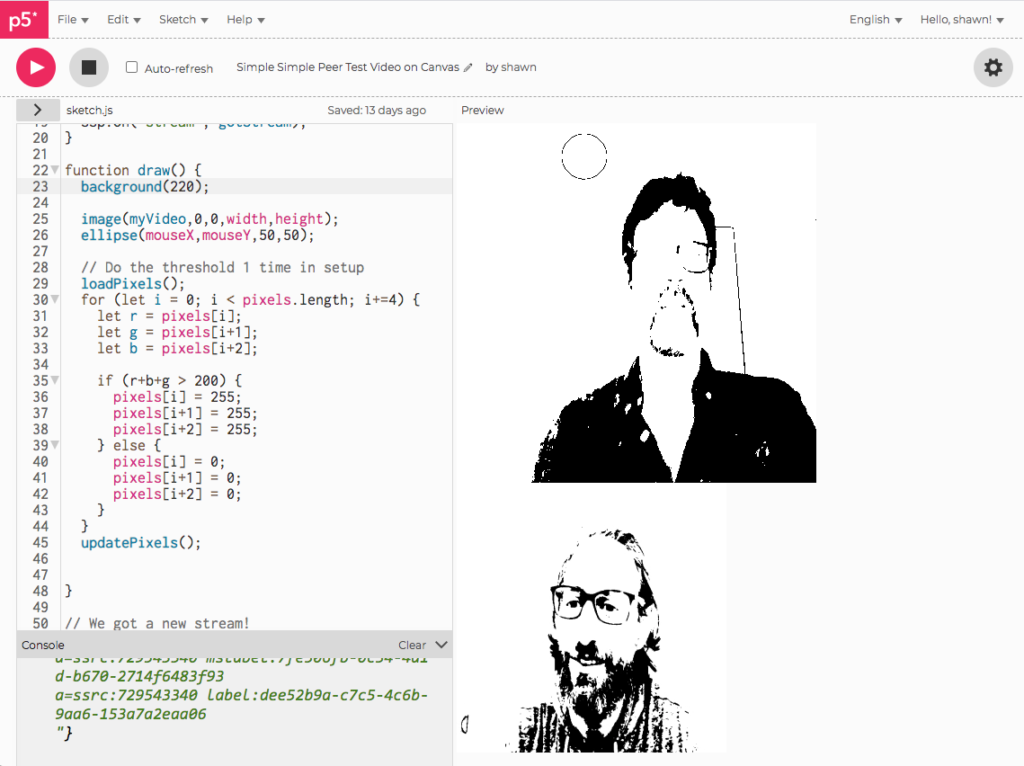
Talking to Craig in a video thresholding example:
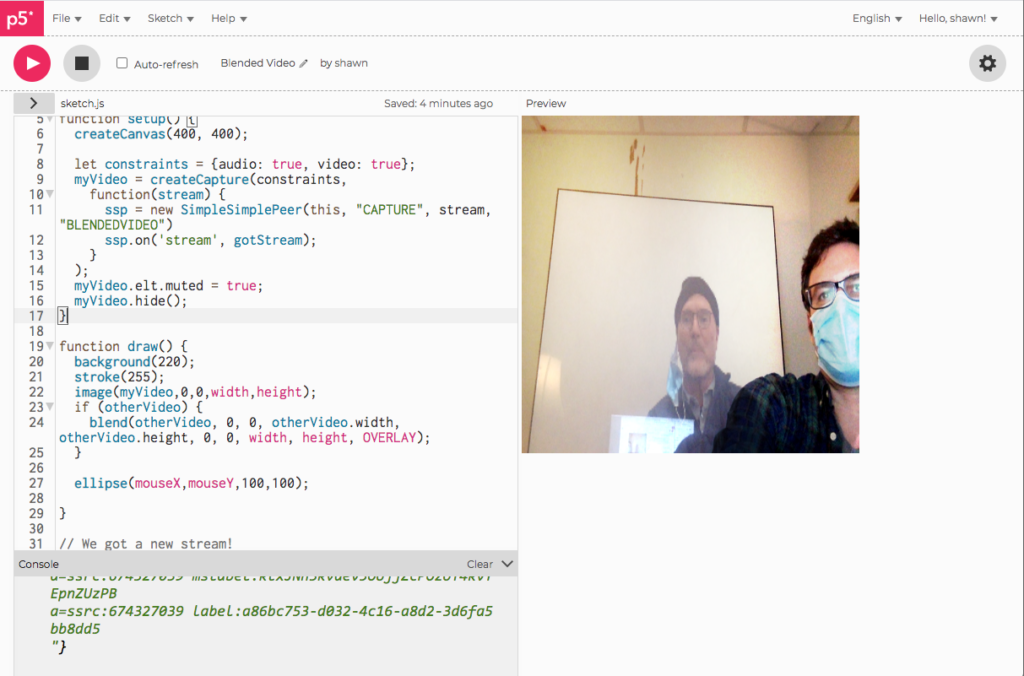
Talking to Dan in an overlay example:
p5LiveMedia is a new p5js library for sharing live audio, video, canvas (as video), and data between users.
Talking to Craig in a video thresholding example:
Talking to Dan in an overlay example:
A new blog post of mine on Make:

More Computer Science Isn’t the Answer
In class today, we talked quite a bit about the effects of computational media on society. I enjoyed the conversation we had about the push for driverless cars which stood as a stand-in for technological progress as a whole.
It would seem that driverless cars as nothing but beneficial, they would save lives, free us from wasted time, and so on. The longer term effects often go unexamined and might not be all that we hope for though. These would likely include longer commutes since we aren’t stuck doing the driving we may choose to live further away. As people are able to move further from work, cities, this would also cause more widespread environmental damage. The more time people spend in cars, they will be more isolated, exercise less, and create more pollution.
Will self driving cars partially solve one problem and end up causing more?
“who gets your phone when you die?”
She wasn’t specifically talking about my phone, more in the abstract, who gets anyone’s phone when they die. The phone to her is this all in one magical device that contains memories and connections, it contains all of the important pictures and is the quickest way to talk to everyone we care for.
Of course, she would wonder who gets so much of us when we die…
In 2007 and 2008, I worked on a project called vLinkr. What follows is a write-up of the initial idea and a few screen caps from the prototype.
vLinkr.com
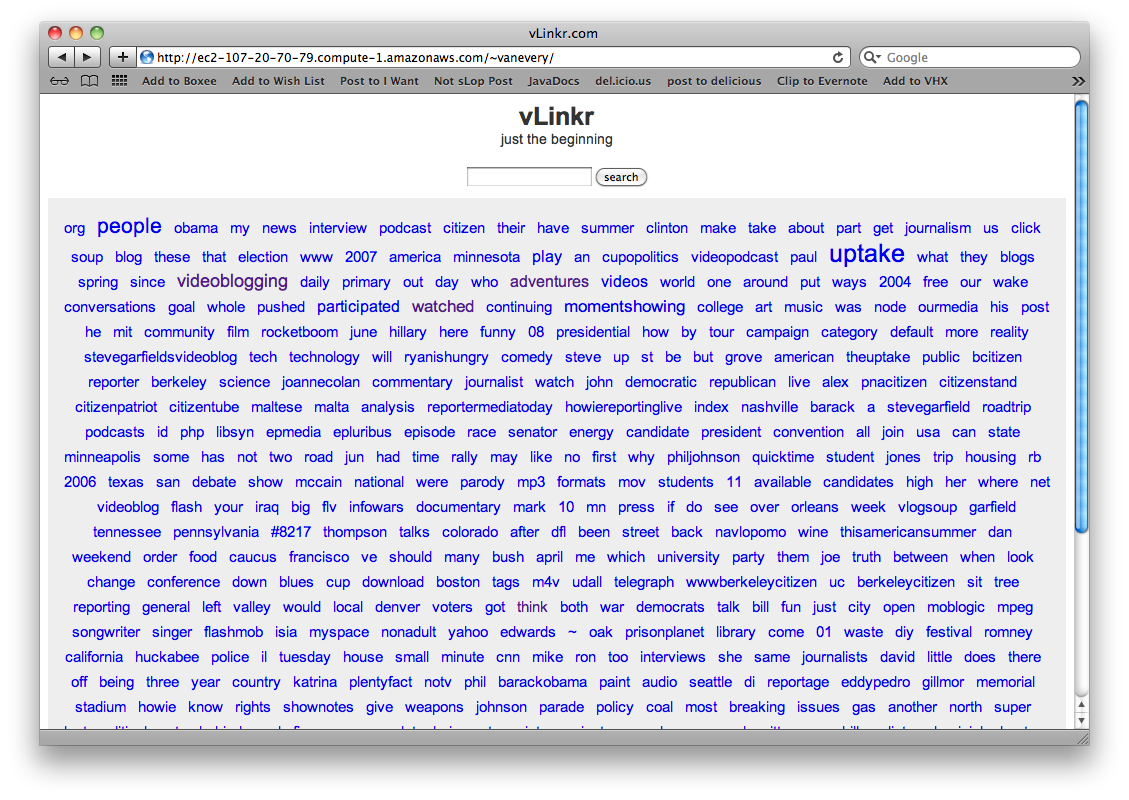
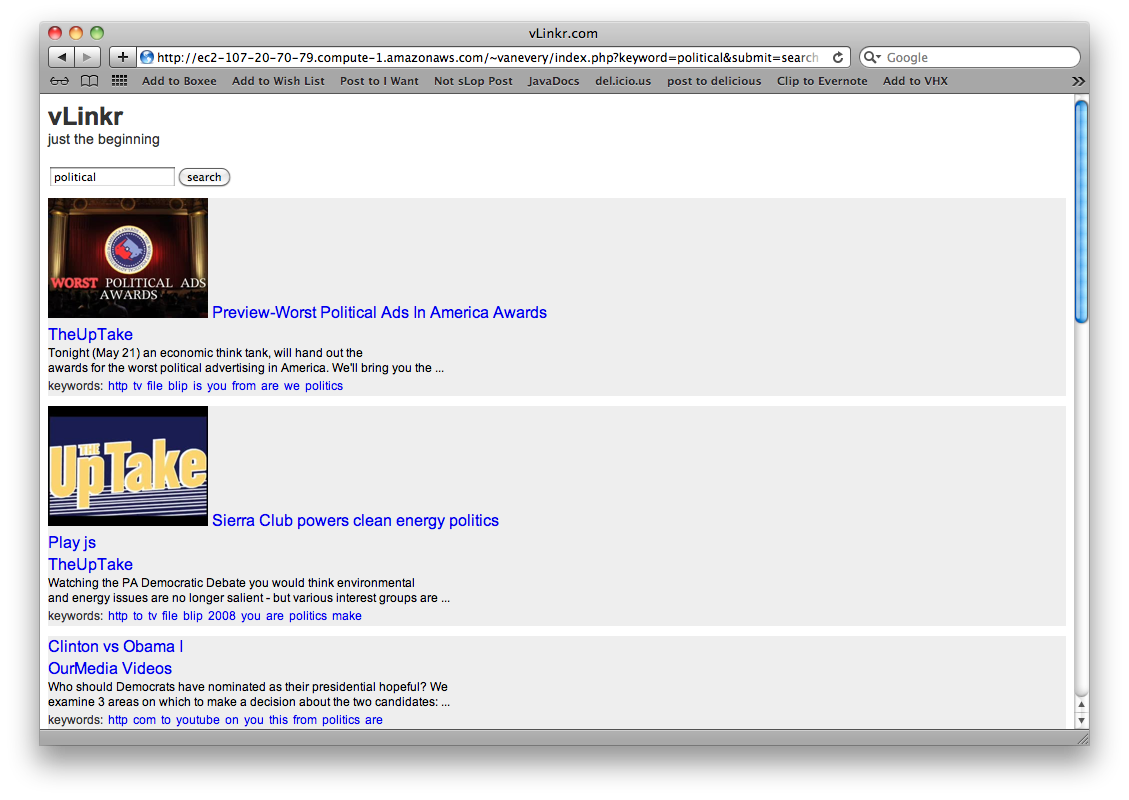
vLinkr’s mission is to enable online media publishers abilities on-par with YouTube and Brightcove while hosting media on their own server on their own terms.
To this end, vLinkr is developing a suite of open source audio and video publishing tools that integrate with popular open source content management systems (initially WordPress and Drupal). Since these tools will be open source, it is hoped that others will help to improve and extend these tools in both functionality and platform reach.
Serious yet small media publishers are under-served by video sharing sites along the lines of YouTube. YouTube in particular is geared towards lower quality, extremely short, often copyright infringing media. Many of these sites follow suit and furthermore retain rights to re-use the media which can be problematic.
On the other side of the spectrum exist companies such as Brightcove whose products are geared towards high end media producers. These tools offer significantly more functionality in the management and control the publishing of online media that larger media companies require. Unfortunately, these tools and services involve significant cost that is often beyond the reach of small media publishers. Also, these tools are often not on the forefront of available technical and social capabilities, rather focusing on generating additional revenue for existing media assets.
vLinkr’s suite of tools seeks to offer a no-compromise solution that is both packaged and open source. (Support and professional services may well enter into this mix.)
Along with the features offered by social media sites (sharing, cross-posting, podcasting, transcoding, ad insertion and commenting) vLinkr seeks to help invent a new type of online media involving audio and video.
The features that currently exist on social media sites can be thought of as retrofits of existing “Web 2.0” technologies onto audio and video content. Unfortunately, these features surround the content rather than integrate with the content. A large part of vLinkr’s mission will be to prototype and release technology that seeks to crack open audio and video and help to make it parse-able, internally searchable and generally more internet like than television/radio like. vLinkr seeks to make audio and video on the internet more than just audio and video on the internet.
One issue with the type of distributed media publishing that vLinkr seeks to support (as opposed to aggregated publishing such as occurs on sites like YouTube) is that the media and is not indexed as well which can make it less “findable”.
This leads to the second portion of vLinkr’s service which is a centralized media data aggregation service. Using existing content syndication and content update infrastructure (RSS and pingback), this service will index most major online media publishing sites along with any individual media site that someone wishes to be added. Additionally, it will leverage the enhanced capabilities of the vLinkr publishing tools increasing the available metadata (audience viewing behavior, comment indexing and so on). These enhanced capabilities will attempt to be standardized so that other developers of publishing tools may generate this enhanced metadata and submit this enhanced metadata as well.
This data aggregation service while offering search and browse capabilities is not intended to be a destination or gateway site, rather it will be primarily used to offer a second set of tools that a media publisher may use on their site to offer search and related content. This will bring the capabilities available more in-line with those offered on existing social media sites and making distributed media more “findable”.
vLinkr believes that competitors in this space (Google Video, Blinkx, MeFeedia, Yahoo Video and so on) make the mistake of bringing the indexed content into their site. vLinkr believes this is somewhat unethical and may be considered copyright infringement. vLinkr, on the other hand will not display the media rather it will just index and link to it therefore helping those using vLinkr tools (and compatible tools) make their media more relevant and findable.
The centralized vLinkr service will have significantly lower infrastructure needs than it’s competitors and will be able to move quickly towards enhanced capabilities not having to house and transcode the media itself.
In terms of capital generation, this data in aggregated form may be sold to advertisers, marketers, media researchers and other interested parties. It may also be used to help target ad placements in content generated by vLinkr users should those users decide to allow advertising.
Any and all feedback or inquiries are encouraged and appreciated.
“We’ve got to make face-to-face time sacred, and we have to bring back the saying we used to hear all the time, and now never hear, ‘Look at me when I talk to you.”
via Clifford Nass, Researcher on Multitasking, Dies at 55 – NYTimes.com.


Destined for the MoMA Design Store!

One of my new students brought in a copy of my book in Chinese. I had no idea it was translated and available. Nice!
Almost a month ago, I was the lucky person who got to write The Listserve message of the day.
In my message I talked about email and I asked people to respond in the hopes that I could engage people in the medium. Well, I am writing now to say it worked, sort of.
First of all, I got more than 2000 messages in response! A number so large that I haven’t actually been able to deal with them in a meaningful way. Many of them were simply replies but many of them were much more that I feel compelled to follow up with. (I think this may represent one of the problems with email ;-))
Part of my problem is that the reply address assigned to the message by the good folks the run The Listerve (shawn.van.every at thelistserve.com) was not not the same as the address I asked people to email (thelisterve at walking-productions.com), instead it had an autoreply. A week or so later they changed it so that the messages to that address were forwarded to me. They also forwarded me all of the messages that they had to that address as well. It now appears as though I have a bunch of duplicate messages.
This is the type of hiccup I really should have expected but I didn’t really think it through. I suppose if I had, I wouldn’t have done what I did and I would have missed out on the fun (and I am serious, reading these messages has been fun). When I get a chance, I hope to pare the number of messages down to unique senders and do another tally.
In any case, if you are someone who sent me a message, I am sorry for the delay and I am still working on the stats but for now I can say that roughly 2,000+ folks out of the 20,000+ on the list replied. A solid 10%!
I will do my best to send a response with the stats.